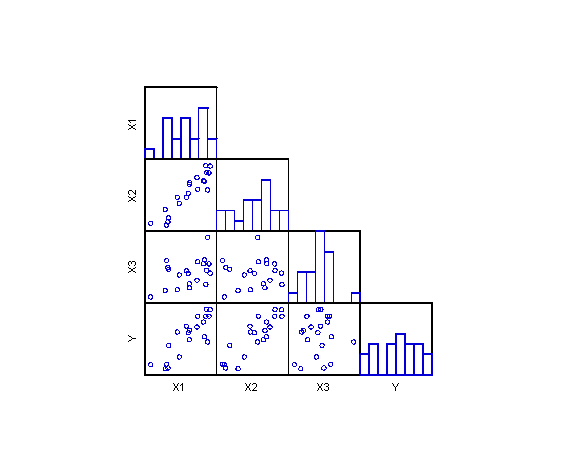
Y = b0 + b1X1 + b2X2 + b3X3 + ewe can estimate the coefficients bk and easily test hypotheses of the form
H0: bk = 0for each coefficient by looking on the regression printout at the p-value of the t-ratio tk* = bk/s{bk} which is distributed as Student t with df=n-p where p is the total number of independent variables (including the constant term).
H1: bk <> 0
H0: b2 = b3 = 0
H1: not both b2 and b3 = 0
H0: b1 = b2
H1: b1 <> b2
H0: b1 = 3, b3 = 5
H1: not both equalities in H0 hold
H0: b2 = b3 = 0To test whether several b2 and b3 are simultaneously zero we contrast
H1: not both b2 and b3 = 0
Y = b0 + b1X1 + b2X2 + b3X3 (full model, F)Q - Why would the reduced model R also be called the constrained model?
Y = b0 + b1X1 (reduced model, R)
The test is based on a comparison of the SSE
of the full and reduced models, denoted SSEF and SSER,
respectively.
It is always true that SSEF <=
SSER, because a model with more parameters always fit the data
as well or better. Thus
F* = (SSER - SSEF)/(dfR - dfF) / (SSEF/dfF) (8.1)In words, F* is the ratio of the difference in SSE between reduced and full models divided by the difference in degrees of freedom between R and F, to the SSE of the full model divided by the degrees of freedom of F.
F* = (R2F - R2R)/(dfR - dfF) / ((1 - R2F)/dfF) (8.2)This formula is particularly useful to test hypotheses from published regression results. (Also, it is the reason why one should not present the adjusted Ra2 alone in published reports, because it makes it more difficult for readers to recover F* if they wish.)
Q - Why is it that SSTO is the same in the full and reduced model?
From the ANOVA table we know that the df of
SSE are n-p where p is the total number of variables including the constant.
For the example above
dfF = n-4so
dfR = n-2
F* = (SSER - SSEF)/((n-2) - (n-4)) / (SSEF/(n-4))Note that the df of the difference between SSER and SSEF is equal to the number of parameters set to zero by the hypothesis.
F* = (SSER - SSEF)/2 / (SSEF/(n-4))
P-value(F*) = P{F(dfR - dfF, dfF)>F*}The decision rule is
if p-value(F*) >= a conclude H0 (8.3a)where a is the level of significance chosen.
if p-value(F*) < a conclude H1 (8.3b)
F(1-a; dfR - dfF, dfF)The decision rule is
if F* <= F(1-a; dfR - dfF, dfF) conclude H0 (8.4a)The critical-value approach is easiest when using printed statistical tables of the F distribution.
if F* > F(1-a; dfR - dfF, dfF) conclude H1 (8.4b)
Q - Why is that?
The strategy for general linear tests is therefore
SSR(X2, X3 | X1) = SSE(X1) - SSE(X1, X2, X3)The extra sum of squares SSR(X2, X3 | X1) is thus the reduction in SSE achieved by including X2 and X3 in a model that already contains X1.
H0: b2 = b3 = 0From the full and reduced models one obtains
H1: not both b2 and b3 = 0
| Full | Reduced | |
| SSE | 98.404888 | 143.119703 |
| R2 | 0.801359 | 0.711097 |
| df of SSE = (n-p) | 16 | 18 |
Using formula (8.1) with SSE one gets
F* = (143.119703 - 98.404888)/(18 - 16) / ((98.404888)/16) = 3.635Equivalently, using formula (8.2) with R2 one gets
F* = (0.801359 - 0.711097)/(18 - 16) / ((1 - 0.801359)/16) = 3.635
Note that while in the full model each coefficient b2 and b3 is individually non-significant, they are jointly significant.
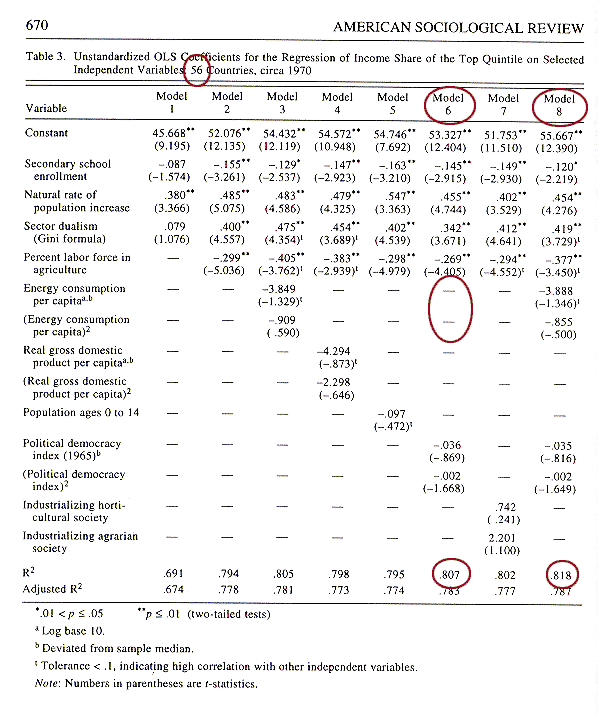
F* = ((.818 - .807)/2) / ((1 - .818)/47) = 1.4203We find the p-value of F* as
depscore = 3.872 + (-.08)educatn + (-.896)l10inc + (.376)female + (.252)cath + (.785)jewi + (.588)none n=256 R2=.124Religion is represented by three (0,1) indicators for Catholic, Jewish and None (with Protestant as the omitted category).
T-ratios are: (10.22) (-1.26) (-3.34) (2.35) (1.19) (2.79) (2.88)
H0: b4 = b5 = b6 = 0To do this one could estimate the reduced model corresponding to the null hypothesis and use the formula above; one can also use STATA (test cath jewi none) to test the joint significance of the three indicators. The program calculates the F-test as F* = 4.40, P{F(3, 249) > F} = 0.0049. Thus one concludes that religion is a significant predictor of the depression score (at the .05 and even .01 level).
H1: not all three b's = 0
H0: b5 = b6Using STATA (test none=jewi) yields F* = .4, P{F(1, 249)>F*} = .526. Thus one concludes that there is no significant difference between categories Jewish and None with respect to depression score.
H1: b5 <> b6
Exhibit: Stata commands for testing effects of religion on depression score
H0: bk = 0This is the usual test reported as the p-value of tk* = bk/s{bk} on the regression printout. One can show that the corresponding F* from the full vs. reduced model comparison is equal to the square of tk*, i.e., F* = (tk*)2. Thus the t-test and F-test for a single coefficient are equivalent.
H1: bk<> 0
H0: b1 = b2 = ... = bp-1 = 0This is the usual test reported as the p-value of F* = MSR/MSE on the regression printout. It follows as a special case of the general formula in which the full model has SSE(X1, X2, ..., Xp-1) with df=n-p and the reduced model has SSE = SSTO with df=n-1.
H1: not all bk (k = 1, ..., p-1) = 0
H0: bq = bq+1 = ... = bp-1 = 0(The notation assumes that the variables are arranged so that the tested variables have subscripts q to p-1.) This is the situation discussed earlier.
H1: not all of the bk in H0 = 0
Other tests can be carried out as a comparison of full & reduced model, using "tricks".
H0: b1 = b2The full model is (omitting the i subscript)
H1: b1 <> b2
Y = b0 + b1X1 + b2X2 + b3X3 + eThe trick is to define the reduced model as
Y = b0 + bc (X1 + X2) + b3X3 + ewhere bc is the "common" regression coefficient of X1 and X2 under H0. One estimates the reduced model as the regression of Y on a new variable calculated as the sum of X1 and X2. Then one calculates F* using formula (8.1) or (8.2). The ful model has df=n-4 and the reduced model has df=n-3 so F* has df=(1, n-4).
H0: b1 = 3, b3 = 5With the full model as above, one derives the reduced model by replacing b1 and b3 by their assumed values under H0 and removing their effects from the dependent variable, as
H1: not both equalities in H0 hold
W = Y - 3X1 - 5X3 = b0 + b2X2 + ewhere W is the new dependent variable. The reduced model is estimated as the regression of W on X2. Then one calculates F* which has df=(2, n-4).
model y = constant + x1 + x2 + x3 + x4 +
x5
estimate
One way to test the hypothesis that the coefficient
of X1 is zero is to use the effect command
hypothesis
effect = x1
test
An alternative method is to use the specify
command
hypothesis
specify x1
= 0
test
Note that this test only repeats the test
already on the regression printout.
To test the hypothesis that the coefficients
of X1, X3, and X4 are simultaneously equal to zero using the effect
command
hypothesis
effect = x1&x3&x4
test
Or, using the specify command:
hypothesis
specify x1
= 0; x3 = 0; x4 = 0
test
Note that equalities are listed on the same line separated by semicolons.
Testing more complicated hypotheses involving equality of coefficients or whether a coefficient has a specific nonzero value is done using the specify command.
To test that the coefficients of X2 and X3
are equal, i.e. that b2
- b3
= 0
hypothesis
specify x2
- x3 = 0
test
To test whether the coefficient of X3 is 3.5
times as large as the coefficient of X5, i.e. that b3
- 3.5b5
= 0
hypothesis
specify x3
- 3.5*x5 = 0
test
To test that coefficients have specific values,
for example that b1=4
and b3=17,
use the commands
hypothesis
specify x1
= 4 ; x3 = 17
test
To test that the difference between coefficient
of X2 and X3 is equal to the specific value 20, use the commands
hypothesis
specify x2
- x3 = 20
test
Examples of actual tests are shown in the next exhibits.
H0: Ab = dwhere A is sxp, b is px1, and d is sx1; s is the number of constraints on the coefficients.
Various specifications of A and d are shown in the following examples, based on a full model with a constant term and variables X1, X2, and X3.
EX: H0: b1
= 0
A = [0 1 0 0] d = [0]
EX: H0: b1
= b2
= 0
A =
|
|
|
|
|
|
|
|
|
|
EX: H0: b1
= b2
A = [0 1 -1 0] d = [0]
The curent edition of NKNW no longer presents this material. The following 3 pages from an older edition (Neter, Wasserman, and Kutner 1990, pp. 306-308) derive the general linear test in matrix notation. (NWK use the notation C for A and h for d.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}